Package aioextensions
High performance functions to work with the async IO.




Rationale
Modern services deal with a bunch of different tasks to perform:
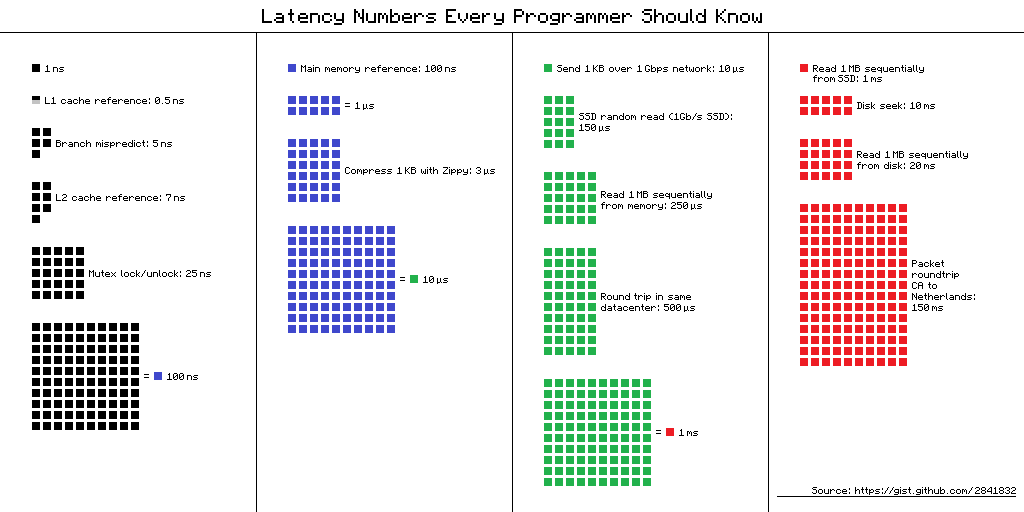
The important thing to note is that tasks can be categorized in two groups:
CPU bound tasks
Those that happen inside the CPU, with very low latency and exploit the full potential of the hardware in the computer.

Examples of these tasks include:
| Task | Latency in seconds |
|---|---|
| CPU computation | 0.000000001 |
| Memory access | 0.0000001 |
| CPU Processing (1KB) | 0.000003 |
| Memory read (1MB) | 0.00025 |
IO bound tasks
Those that happen over a wire that transports data, with very high latencies and do not exploit the full potential of the hardware because the only thing to do is waiting until the data gets to the other end and comes back (round-trip).

Examples of these tasks include:
| Task | Latency in seconds |
|---|---|
| Disk access | 0.00015 |
| HTTP to localhost | 0.0005 |
| Disk read (1MB) | 0.02 |
| HTTP to internet | 0.15 |
Speed and costs matter
At the end of the day, we want to minimize the amount of cost per user served by the program, server, or service while maximizing the user perception of speed.
In order to achieve this we need a model that allows us to exploit all CPU cores and installed hardware in the machine, while maintaining the ability to query large amounts of high-latency external services over the network: databases, caches, storage, distributed queues, or input from multiple users.
Concurrency model
Python's Async IO has a concurrency model based on an event loop, which is responsible for executing the code, collecting and processing what's needed.
This event-loop executes in the main thread of the Python interpreter and therefore it's limited by the GIL, so it's alone unable to exploit all hardware installed in the host.
However:
- CPU intensive work can be sent to a pool of processes, far from the event-loop and thus being able to bypass the GIL, exploiting many CPU cores in the machine, and leaving the event-loop schedule and coordinate incoming requests.
- IO intensive work can be sent to a pool of threads, far from the event-loop and thus being able to wait for high-latency operations without interrupting the event-loop work.
There is an important difference:
- Work done by a pool of processes is executed in parallel: all CPU cores are being used.
- Work done by a pool of threads is done concurrently: tasks execution is overlapping, but not necessarily parallel: only 1 task can use the CPU while the remaining ones are waiting the GIL.
Solving CPU bound tasks efficiently
The optimal way to perform CPU bound tasks is to send them to separate processses in order to bypass the GIL.
Usage
>>> from aioextensions import collect, in_process, run
>>> def cpu_bound_task(id: str):
print(f'doing: {id}')
# Imagine here something that uses a lot the CPU
# For example: this complex mathematical operation
for _ in range(10): 3**20000000
print(f'returning: {id}')
return id
>>> async def main():
results = await collect([
# in_process sends the task to a pool of processes
in_process(cpu_bound_task, id)
# Let's solve 5 of those tasks in parallel!
for id in range(5)
])
print(f'results: {results}')
>>> run(main())
# I have 4 CPU cores in my machine
doing: 0
doing: 1
doing: 2
doing: 3
returning: 1
doing: 4
returning: 2
returning: 3
returning: 0
returning: 4
results: (0, 1, 2, 3, 4)
As expected, all CPU cores were used and we were hardware-efficient!
Solving IO bound tasks efficiently
The optimal way to perform IO bound tasks is to send them to separate threads. This does not bypass the GIL. However, threads will be in idle state most of the time, waiting high-latency operations to complete.
Usage
>>> from aioextensions import collect, in_thread, run
>>> from time import sleep, time
>>> def io_bound_task(id: str):
print(f'time: {time()}, doing: {id}')
# Imagine here something with high latency
# For example: a call to the database, or this sleep
sleep(1)
print(f'time: {time()}, returning: {id}')
return id
>>> async def main():
results = await collect([
# in_thread sends the task to a pool of threads
in_thread(io_bound_task, id)
# Let's solve 5 of those tasks concurrently!
for id in range(5)
])
print(f'time: {time()}, results: {results}')
>>> run(main)
time: 1597623831, doing: 0
time: 1597623831, doing: 1
time: 1597623831, doing: 2
time: 1597623831, doing: 3
time: 1597623831, doing: 4
time: 1597623832, returning: 0
time: 1597623832, returning: 4
time: 1597623832, returning: 3
time: 1597623832, returning: 2
time: 1597623832, returning: 1
time: 1597623832, results: (0, 1, 2, 3, 4)
As expected, all tasks were executed concurrently. This means that instead of waiting five seconds for five tasks (serially) we just waited one second for all of them.
Installing
$ pip install aioextensions
# Optionally if you want uvloop support (not available on Windows)
$ pip install aioextensions[full]
Using
>>> from aioextensions import * # to import everything
Please read the documentation bellow for more details about every function.
Expand source code Browse git
"""High performance functions to work with the async IO.
[](
https://pypi.org/project/aioextensions)
[](
https://fluidattacks.github.io/aioextensions/)
[](
https://pypi.org/project/aioextensions)
[](
https://pypi.org/project/aioextensions)
[](
https://fluidattacks.github.io/aioextensions/)
[](
https://github.com/fluidattacks/aioextensions/blob/latest/LICENSE.md)
# Rationale
Modern services deal with a bunch of different tasks to perform:

The important thing to note is that tasks can be categorized in two groups:
## CPU bound tasks
Those that happen inside the CPU, with very low latency and exploit the full
potential of the hardware in the computer.

Examples of these tasks include:
| Task | Latency in seconds |
|----------------------|-------------------:|
| CPU computation | 0.000000001 |
| Memory access | 0.0000001 |
| CPU Processing (1KB) | 0.000003 |
| Memory read (1MB) | 0.00025 |
## IO bound tasks
Those that happen over a wire that transports data, with very high latencies
and do not exploit the full potential of the hardware because the only thing to
do is waiting until the data gets to the other end and comes back (round-trip).

Examples of these tasks include:
| Task | Latency in seconds |
|----------------------|-------------------:|
| Disk access | 0.00015 |
| HTTP to localhost | 0.0005 |
| Disk read (1MB) | 0.02 |
| HTTP to internet | 0.15 |
# Speed and costs matter
At the end of the day, we want to minimize the amount of cost per user served
by the program, server, or service while maximizing the user perception of
speed.
In order to achieve this we need a model that allows us to exploit all CPU
cores and installed hardware in the machine, while maintaining the ability to
query large amounts of high-latency external services over the network:
databases, caches, storage, distributed queues, or input from multiple users.
# Concurrency model
Python's Async IO has a concurrency model based on an **event loop**, which
is responsible for executing the code, collecting and processing what's needed.
This event-loop executes in the main thread of the Python interpreter and
therefore it's limited by the [GIL](https://realpython.com/python-gil), so it's
alone unable to exploit all hardware installed in the host.
However:
- CPU intensive work can be sent to a pool of processes, far from the
event-loop and thus being able to bypass the
[GIL](https://realpython.com/python-gil), exploiting many CPU cores in
the machine, and leaving the event-loop schedule and coordinate incoming
requests.
- IO intensive work can be sent to a pool of threads, far from the event-loop
and thus being able to wait for high-latency operations without
interrupting the event-loop work.
There is an important difference:
- Work done by a pool of processes is executed in parallel: all CPU cores are
being used.
- Work done by a pool of threads is done concurrently: tasks execution is
overlapping, but not necessarily parallel: only 1 task can use the CPU
while the remaining ones are waiting the
[GIL](https://realpython.com/python-gil).
## Solving CPU bound tasks efficiently
The optimal way to perform CPU bound tasks is to send them to separate
processses in order to bypass the [GIL](https://realpython.com/python-gil).
Usage:
>>> from aioextensions import collect, in_process, run
>>> def cpu_bound_task(id: str):
print(f'doing: {id}')
# Imagine here something that uses a lot the CPU
# For example: this complex mathematical operation
for _ in range(10): 3**20000000
print(f'returning: {id}')
return id
>>> async def main():
results = await collect([
# in_process sends the task to a pool of processes
in_process(cpu_bound_task, id)
# Let's solve 5 of those tasks in parallel!
for id in range(5)
])
print(f'results: {results}')
>>> run(main())
# I have 4 CPU cores in my machine
doing: 0
doing: 1
doing: 2
doing: 3
returning: 1
doing: 4
returning: 2
returning: 3
returning: 0
returning: 4
results: (0, 1, 2, 3, 4)
As expected, all CPU cores were used and we were hardware-efficient!
## Solving IO bound tasks efficiently
The optimal way to perform IO bound tasks is to send them to separate
threads. This does not bypass the [GIL](https://realpython.com/python-gil).
However, threads will be in idle state most of the time, waiting high-latency
operations to complete.
Usage:
>>> from aioextensions import collect, in_thread, run
>>> from time import sleep, time
>>> def io_bound_task(id: str):
print(f'time: {time()}, doing: {id}')
# Imagine here something with high latency
# For example: a call to the database, or this sleep
sleep(1)
print(f'time: {time()}, returning: {id}')
return id
>>> async def main():
results = await collect([
# in_thread sends the task to a pool of threads
in_thread(io_bound_task, id)
# Let's solve 5 of those tasks concurrently!
for id in range(5)
])
print(f'time: {time()}, results: {results}')
>>> run(main)
time: 1597623831, doing: 0
time: 1597623831, doing: 1
time: 1597623831, doing: 2
time: 1597623831, doing: 3
time: 1597623831, doing: 4
time: 1597623832, returning: 0
time: 1597623832, returning: 4
time: 1597623832, returning: 3
time: 1597623832, returning: 2
time: 1597623832, returning: 1
time: 1597623832, results: (0, 1, 2, 3, 4)
As expected, all tasks were executed concurrently. This means that instead of
waiting five seconds for five tasks (serially) we just waited one second for
all of them.
# Installing
$ pip install aioextensions
# Optionally if you want uvloop support (not available on Windows)
$ pip install aioextensions[full]
# Using
>>> from aioextensions import * # to import everything
Please read the documentation bellow for more details about every function.
"""
# Standard library
import asyncio
from collections import (
deque,
)
from concurrent.futures import (
Executor,
ProcessPoolExecutor,
ThreadPoolExecutor,
)
from contextlib import (
asynccontextmanager,
suppress,
)
from functools import (
partial,
wraps,
)
from itertools import (
tee,
)
from os import (
cpu_count,
)
from typing import (
Any,
AsyncGenerator,
AsyncIterator,
Awaitable,
Callable,
cast,
Deque,
Dict,
Generator,
Iterable,
Optional,
Tuple,
Type,
TypeVar,
Union,
)
# Third party libraries
try:
# Attempt to install uvloop (optional dependency)
import uvloop
UVLOOP = uvloop
except ImportError:
UVLOOP = None
# Constants
F = TypeVar("F", bound=Callable[..., Any]) # pylint: disable=invalid-name
S = TypeVar("S") # pylint: disable=invalid-name
T = TypeVar("T") # pylint: disable=invalid-name
Y = TypeVar("Y") # pylint: disable=invalid-name
# Linters
# pylint: disable=unsubscriptable-object
def run(coroutine: Awaitable[T], *, debug: bool = False) -> T:
"""Execute an asynchronous function synchronously and return its result.
Usage:
>>> async def do(a, b=0):
await something
return a + b
>>> run(do(1, b=2))
>>> 3
This function acts as a drop-in replacement of asyncio.run and
installs `uvloop` (the fastest event-loop implementation out there) if
available.
.. tip::
Use this as the entrypoint for your program.
"""
if UVLOOP is not None:
UVLOOP.install()
return asyncio.run(coroutine, debug=debug)
async def in_thread(
function: Callable[..., T],
*args: Any,
**kwargs: Any,
) -> T:
"""Execute `function(*args, **kwargs)` in the configured thread pool.
This is the most performant wrapper for IO bound and high-latency tasks.
Every task will be assigned at most one thread, if there are more tasks
than threads in the pool the excess will be executed in FIFO order.
Spawning a million IO bound tasks with this function has a very small
memory footprint.
.. warning::
Executing CPU intensive work here is a bad idea because of the
limitations that the [GIL](https://realpython.com/python-gil) imposes.
See `in_process` for a CPU performant alternative.
"""
_ensure_thread_pool_is_initialized()
return await asyncio.get_running_loop().run_in_executor(
THREAD_POOL.pool,
partial(function, *args, **kwargs),
)
async def in_process(
function: Callable[..., T],
*args: Any,
**kwargs: Any,
) -> T:
"""Execute `function(*args, **kwargs)` in the configured process pool.
This is the most performant wrapper for CPU bound and low-latency tasks.
Tasks executed in a process pool bypass the
[GIL](https://realpython.com/python-gil) and can consume all CPU cores
available in the host if needed.
Every task will be assigned at most one process, if there are more tasks
than processes in the pool the excess will be executed in FIFO order.
.. warning::
Executing IO intensive work here is possible, but spawning a process
has some overhead that can be avoided using threads at no performance
expense.
See `in_thread` for an IO performant alternative.
"""
_ensure_process_pool_is_initialized()
return await asyncio.get_running_loop().run_in_executor(
PROCESS_POOL.pool,
partial(function, *args, **kwargs),
)
def rate_limited(
*,
max_calls: int,
max_calls_period: Union[float, int],
min_seconds_between_calls: Union[float, int] = 0,
) -> Callable[[F], F]:
"""Decorator to turn an asynchronous function into a rate limited one.
The decorated function won't be able to execute more than `max_calls` times
over a period of `max_calls_period` seconds. The excess will be queued in
FIFO mode.
Aditionally, it's guaranteed that no successive calls can be performed
faster than `min_seconds_between_calls` seconds.
Usage:
If you want to perform at most 2 calls to a database per second:
>>> @rate_limited(
max_calls=2,
max_calls_period=1,
min_seconds_between_calls=0.2,
)
async def query(n):
await something
print(f'time: {time()}, doing: {n}')
>>> await collect(map(query, range(10)))
Output:
```
time: 1597706698.0, doing: 0
time: 1597706698.2, doing: 1
time: 1597706699.0, doing: 2
time: 1597706699.2, doing: 3
time: 1597706700.0, doing: 4
time: 1597706700.2, doing: 5
time: 1597706701.0, doing: 6
time: 1597706701.2, doing: 7
time: 1597706702.0, doing: 8
time: 1597706702.2, doing: 9
```
.. tip::
Use `min_seconds_between_calls` as an anti-burst system. This can, for
instance, lower your bill in DynamoDB or prevent a cooldown period
(also know as ban) by a firewall.
This decorator creates a `max_calls` sized data structure.
"""
if max_calls < 1:
raise ValueError("max_calls must be >= 1")
if max_calls_period <= 0:
raise ValueError("max_calls_period must be > 0")
if min_seconds_between_calls < 0:
raise ValueError("min_seconds_between_calls must be >= 0")
def decorator(function: F) -> F:
lock = None
waits: Deque[float] = deque()
@wraps(function)
async def wrapper(*args: Any, **kwargs: Any) -> Any:
nonlocal lock
lock = lock or asyncio.Lock()
loop = asyncio.get_event_loop()
async with lock:
if waits:
# Anti burst control system:
# wait until the difference between the most recent call
# and the current call is >= min_seconds_between_calls
await asyncio.sleep(
waits[-1] + min_seconds_between_calls - loop.time()
)
while len(waits) >= max_calls:
# Rate limit control system:
# wait until the least recent call and the current call
# is >= max_calls_period
await asyncio.sleep(
waits.popleft() + max_calls_period - loop.time()
)
waits.append(loop.time())
return await function(*args, **kwargs)
return cast(F, wrapper)
return decorator
async def collect(
awaitables: Iterable[Awaitable[T]],
*,
workers: int = 1024,
) -> Tuple[T, ...]:
"""Resolve concurrently the input stream and return back in the same order.
At any point in time there will be at most _number of `workers`_
tasks being resolved concurrently.
Aditionally, the algorithm makes sure that at any point in time every
worker is busy.
Args:
awaitables: An iterable (generator, list, tuple, set, etc) of
awaitables (coroutine, asyncio.Task, or asyncio.Future).
workers: The number of independent workers that will be processing
the input stream.
Returns:
A tuple with the results of executing each awaitable in the event loop.
Results are returned in the same order of the input stream.
Usage:
>>> async def do(n):
print(f'running: {n}')
await sleep(1)
print(f'returning: {n}')
return n
>>> iterable = map(do, range(5))
>>> results = await collect(iterable, workers=2)
>>> print(f'results: {results}')
Output:
```
running: 0
running: 1
returning: 0
returning: 1
running: 2
running: 3
returning: 2
returning: 3
running: 4
returning: 4
results: (0, 1, 2, 3, 4)
```
.. tip::
This is similar to asyncio.as_completed. However results are returned
in order and allows you to control how much resources are consumed
throughout the execution, for instance:
- How many open files will be opened at the same time
- How many HTTP requests will be performed to a service (rate limit)
- How many sockets will be opened concurrently
- Etc
This is useful for finite resources, for instance: the number
of sockets provided by the operative system is limited; going beyond it
would make the kernel to kill the program abruptly.
If awaitables is an instance of Sized (has `__len__` prototype).
This function will launch at most `len(awaitables)` workers.
"""
return tuple(
[
await elem
for elem in resolve(
awaitables,
workers=workers,
worker_greediness=0,
)
]
)
def resolve( # noqa: mccabe
awaitables: Iterable[Awaitable[T]],
*,
workers: int = 1024,
worker_greediness: int = 0,
) -> Iterable[Awaitable[T]]:
"""Resolve concurrently the input stream and yield back in the same order.
At any point in time there will be at most _number of `workers`_
tasks being resolved concurrently.
Aditionally, the algorithm makes sure that at any point in time every
worker is busy (if greediness allow them).
Args:
awaitables: An iterable (generator, list, tuple, set, etc) of
awaitables (coroutine, asyncio.Task, or asyncio.Future).
workers: The number of independent workers that will be processing
the input stream.
worker_greediness: How much tasks can a worker process before waiting
for you to retrieve its results. 0 means unlimited. Set to non-zero
in order to upper-bound memory usage throughout the execution.
Yields:
A future with the result of the next ready task. Futures are yielded in
the same order of the input stream.
Usage:
>>> async def do(n):
print(f'running: {n}')
await asyncio.sleep(1)
print(f'returning: {n}')
return n
>>> iterable = map(do, range(5))
>>> for next in resolve(iterable, workers=2):
try:
print(f'got resolved result: {await next}')
except:
pass # Handle possible exceptions
Output:
```
running: 0
running: 1
returning: 0
returning: 1
got resolved result: 0
got resolved result: 1
running: 2
running: 3
returning: 2
returning: 3
got resolved result: 2
got resolved result: 3
running: 4
returning: 4
got resolved result: 4
```
.. tip::
This is similar to asyncio.as_completed. However results are returned
in order and allows you to control how much resources are consumed
throughout the execution, for instance:
- How many open files will be opened at the same time
- How many HTTP requests will be performed to a service (rate limit)
- How many sockets will be opened concurrently
- Etc
This is useful for finite resources, for instance: the number
of sockets provided by the operative system is limited; going beyond it
would make the kernel to kill the program abruptly.
If awaitables is an instance of Sized (has `__len__` prototype).
This function will launch at most `len(awaitables)` workers.
"""
if workers < 1:
raise ValueError("workers must be >= 1")
if worker_greediness < 0:
raise ValueError("worker_greediness must be >= 0")
if hasattr(awaitables, "__len__"):
workers = min(workers, len(awaitables)) # type: ignore
loop = asyncio.get_event_loop()
store: Dict[int, asyncio.Queue] = {}
stream, stream_copy = tee(enumerate(awaitables))
stream_finished = asyncio.Event()
workers_up = asyncio.Event()
workers_tasks: Dict[int, asyncio.Task] = {}
async def worker() -> None:
done: asyncio.Queue = asyncio.Queue(worker_greediness)
for index, awaitable in stream:
store[index] = done
future = loop.create_future()
future.set_result(await schedule(awaitable, loop=loop))
await done.put(future)
workers_up.set()
workers_up.set()
stream_finished.set()
async def start_workers() -> None:
for index in range(workers):
if stream_finished.is_set():
break
workers_tasks[index] = asyncio.create_task(worker())
await force_loop_cycle()
await workers_up.wait()
async def get_one(index: int) -> Awaitable[T]:
if not workers_tasks:
await start_workers()
awaitable = await store.pop(index).get()
result: Awaitable[T] = (await awaitable).result()
return result
for index, _ in stream_copy:
yield cast(Awaitable[T], get_one(index))
async def force_loop_cycle() -> None:
"""Force the event loop to perform one cycle.
This can be used to suspend the execution of the current coroutine and
yield control back to the event-loop until the next cycle.
Can be seen as a forceful switch of control between threads.
Useful for cooperative initialization.
Usage:
>>> await forceforce_loop_cycle()
"""
await asyncio.sleep(0)
async def generate_in_thread(
generator_func: Callable[..., Generator[Y, S, None]],
*args: Any,
**kwargs: Any,
) -> AsyncGenerator[Y, S]:
"""Mimic `generator_func(*args, **kwargs)` in the configured thread pool.
Note that `generator_func(*args, **kwargs)` may return a generator or an
interator and both cases are handled rightfully.
Usage:
>>> from os import scandir
>>> async for entry in generate_in_thread(scandir, '.'):
print(entry.name)
Output:
```
.gitignore
LICENSE.md
README.md
...
```
Calls to the generator are done serially and not concurrently.
The benefit of wrapping a generator with this function is that the
event-loop is free to schedule and wait another tasks in the mean time.
For instance, in a web server.
"""
gen: Generator[Y, S, None] = generator_func(*args, **kwargs)
gen_sent: Any = None
def gen_next(val: S) -> Y:
with suppress(StopIteration):
return gen.send(val) if hasattr(gen, "send") else next(gen)
raise StopAsyncIteration()
while True:
try:
gen_sent = yield await in_thread(gen_next, gen_sent)
except StopAsyncIteration:
return
def schedule(
awaitable: Awaitable[T],
*,
loop: Optional[asyncio.AbstractEventLoop] = None,
) -> "Awaitable[asyncio.Future[T]]":
"""Schedule an awaitable in the event loop and return a wrapper for it.
Usage:
>>> async def do(n):
print(f'running: {n}')
await sleep(1)
print(f'returning: {n}')
>>> task = schedule(do(3)) # Task is executing in the background now
>>> print('other work is being done here')
>>> task_result = await task # Wait until the task is ready
>>> print(f'result: {task_result.result()}') # may rise if do() raised
Output:
```
other work is being done here
doing: 3
returning: 3
3
```
This works very similar to asyncio.create_task. The main difference is that
the result (or exception) can be accessed via exception() or result()
methods.
If an exception was raised by the awaitable, it will be propagated only at
the moment result() is called and never otherwise.
"""
wrapper = (loop or asyncio.get_event_loop()).create_future()
def _done_callback(future: asyncio.Future) -> None:
if not wrapper.done(): # pragma: no cover
wrapper.set_result(future)
asyncio.create_task(awaitable).add_done_callback(_done_callback)
return wrapper
class Semaphore(asyncio.Semaphore):
"""Same as `asyncio.Semaphore` plus some useful methods."""
@asynccontextmanager
async def acquire_many(self, times: int) -> AsyncIterator[None]:
"""Acquire a semaphore many times, and release on exit.
Usage:
>>> async with semaphore.acquire_many(5):
# Work with shared resource
...
"""
if times <= 0:
raise ValueError("times must be >= 1")
try:
await collect([self.acquire() for _ in range(times)])
yield
finally:
for _ in range(times):
self.release()
class BoundedSemaphore(Semaphore, asyncio.BoundedSemaphore):
"""Same as `asyncio.BoundedSemaphore` plus some useful methods."""
def _ensure_process_pool_is_initialized() -> None:
if not PROCESS_POOL.initialized:
PROCESS_POOL.initialize(max_workers=CPU_CORES)
def _ensure_thread_pool_is_initialized() -> None:
if not THREAD_POOL.initialized:
THREAD_POOL.initialize(max_workers=10 * CPU_CORES)
class ExecutorPool:
"""Object representing a pool of Processes or Threads.
The actual pool is created at `initialization` time
and it is empty until that.
"""
def __init__(
self,
cls: Union[
Type[ProcessPoolExecutor],
Type[ThreadPoolExecutor],
],
) -> None:
self._cls = cls
self._pool: Optional[Executor] = None
def initialize(self, *, max_workers: Optional[int] = None) -> None:
"""Initialize the executor with a cap of at most `max_workers`.
Workers are created on-demand as needed or never created at all
if never needed.
"""
if self._pool is not None:
self._pool.shutdown(wait=False)
self._pool = self._cls(max_workers=max_workers)
def shutdown(self, *, wait: bool) -> None:
"""Shut down the executor and (optionally) waits for workers to finish."""
if self._pool is not None:
self._pool.shutdown(wait=wait)
self._pool = None
@property
def pool(self) -> Executor:
"""Low level pool of workers held by the executor, may be None."""
if self._pool is None:
raise RuntimeError("Must call initialize first")
return self._pool
@property
def initialized(self) -> bool:
"""Return true if the executor is initialized and ready to process."""
return self._pool is not None
def run_decorator(function: F) -> F:
"""Decorator to turn an asynchronous function into a synchronous one.
Usage:
>>> @run_decorator
async def do(a, b=0):
return a + b
>>> do(1, b=2)
Output:
```
3
```
This can be used as a bridge between synchronous and asynchronous code.
We use it mostly in tests for its convenience over pytest-asyncio plugin.
"""
@wraps(function)
def wrapper(*args: Any, **kwargs: Any) -> Any:
return run(function(*args, **kwargs))
return cast(F, wrapper)
# Constants
CPU_CORES: int = cpu_count() or 1
"""Number of CPU cores in the host system."""
PROCESS_POOL: ExecutorPool = ExecutorPool(ProcessPoolExecutor)
"""Process pool used by `in_process` function to execute work.
Preconfigured to launch at most `CPU_CORES` processes (if needed).
Proceses are created on the first `in_process` call, one by one as needed
or never launched otherwise.
"""
THREAD_POOL: ExecutorPool = ExecutorPool(ThreadPoolExecutor)
"""Thread pool used by `in_thread` function to execute work.
Preconfigured to launch at most 10 * `CPU_CORES` threads (if needed).
Threads are created on the first `in_thread` call, one by one as needed,
or never launched otherwise.
"""Global variables
var CPU_CORES : int-
Number of CPU cores in the host system.
var PROCESS_POOL : ExecutorPool-
Process pool used by
in_process()function to execute work.Preconfigured to launch at most
CPU_CORESprocesses (if needed).Proceses are created on the first
in_process()call, one by one as needed or never launched otherwise. var THREAD_POOL : ExecutorPool-
Thread pool used by
in_thread()function to execute work.Preconfigured to launch at most 10 *
CPU_CORESthreads (if needed).Threads are created on the first
in_thread()call, one by one as needed, or never launched otherwise.
Functions
def run(coroutine: Awaitable[~T], *, debug: bool = False) ‑> ~T-
Execute an asynchronous function synchronously and return its result.
Usage
>>> async def do(a, b=0): await something return a + b>>> run(do(1, b=2))>>> 3This function acts as a drop-in replacement of asyncio.run and installs
uvloop(the fastest event-loop implementation out there) if available.Tip
Use this as the entrypoint for your program.
Expand source code Browse git
def run(coroutine: Awaitable[T], *, debug: bool = False) -> T: """Execute an asynchronous function synchronously and return its result. Usage: >>> async def do(a, b=0): await something return a + b >>> run(do(1, b=2)) >>> 3 This function acts as a drop-in replacement of asyncio.run and installs `uvloop` (the fastest event-loop implementation out there) if available. .. tip:: Use this as the entrypoint for your program. """ if UVLOOP is not None: UVLOOP.install() return asyncio.run(coroutine, debug=debug) async def in_thread(function: Callable[..., ~T], *args: Any, **kwargs: Any) ‑> ~T-
Execute
function(*args, **kwargs)in the configured thread pool.This is the most performant wrapper for IO bound and high-latency tasks.
Every task will be assigned at most one thread, if there are more tasks than threads in the pool the excess will be executed in FIFO order.
Spawning a million IO bound tasks with this function has a very small memory footprint.
Warning
Executing CPU intensive work here is a bad idea because of the limitations that the GIL imposes.
See
in_process()for a CPU performant alternative.Expand source code Browse git
async def in_thread( function: Callable[..., T], *args: Any, **kwargs: Any, ) -> T: """Execute `function(*args, **kwargs)` in the configured thread pool. This is the most performant wrapper for IO bound and high-latency tasks. Every task will be assigned at most one thread, if there are more tasks than threads in the pool the excess will be executed in FIFO order. Spawning a million IO bound tasks with this function has a very small memory footprint. .. warning:: Executing CPU intensive work here is a bad idea because of the limitations that the [GIL](https://realpython.com/python-gil) imposes. See `in_process` for a CPU performant alternative. """ _ensure_thread_pool_is_initialized() return await asyncio.get_running_loop().run_in_executor( THREAD_POOL.pool, partial(function, *args, **kwargs), ) async def in_process(function: Callable[..., ~T], *args: Any, **kwargs: Any) ‑> ~T-
Execute
function(*args, **kwargs)in the configured process pool.This is the most performant wrapper for CPU bound and low-latency tasks.
Tasks executed in a process pool bypass the GIL and can consume all CPU cores available in the host if needed.
Every task will be assigned at most one process, if there are more tasks than processes in the pool the excess will be executed in FIFO order.
Warning
Executing IO intensive work here is possible, but spawning a process has some overhead that can be avoided using threads at no performance expense.
See
in_thread()for an IO performant alternative.Expand source code Browse git
async def in_process( function: Callable[..., T], *args: Any, **kwargs: Any, ) -> T: """Execute `function(*args, **kwargs)` in the configured process pool. This is the most performant wrapper for CPU bound and low-latency tasks. Tasks executed in a process pool bypass the [GIL](https://realpython.com/python-gil) and can consume all CPU cores available in the host if needed. Every task will be assigned at most one process, if there are more tasks than processes in the pool the excess will be executed in FIFO order. .. warning:: Executing IO intensive work here is possible, but spawning a process has some overhead that can be avoided using threads at no performance expense. See `in_thread` for an IO performant alternative. """ _ensure_process_pool_is_initialized() return await asyncio.get_running_loop().run_in_executor( PROCESS_POOL.pool, partial(function, *args, **kwargs), ) def rate_limited(*, max_calls: int, max_calls_period: Union[float, int], min_seconds_between_calls: Union[float, int] = 0) ‑> Callable[[~F], ~F]-
Decorator to turn an asynchronous function into a rate limited one.
The decorated function won't be able to execute more than
max_callstimes over a period ofmax_calls_periodseconds. The excess will be queued in FIFO mode.Aditionally, it's guaranteed that no successive calls can be performed faster than
min_seconds_between_callsseconds.Usage
If you want to perform at most 2 calls to a database per second:
>>> @rate_limited( max_calls=2, max_calls_period=1, min_seconds_between_calls=0.2, ) async def query(n): await something print(f'time: {time()}, doing: {n}')>>> await collect(map(query, range(10)))Output
time: 1597706698.0, doing: 0 time: 1597706698.2, doing: 1 time: 1597706699.0, doing: 2 time: 1597706699.2, doing: 3 time: 1597706700.0, doing: 4 time: 1597706700.2, doing: 5 time: 1597706701.0, doing: 6 time: 1597706701.2, doing: 7 time: 1597706702.0, doing: 8 time: 1597706702.2, doing: 9Tip
Use
min_seconds_between_callsas an anti-burst system. This can, for instance, lower your bill in DynamoDB or prevent a cooldown period (also know as ban) by a firewall.This decorator creates a
max_callssized data structure.Expand source code Browse git
def rate_limited( *, max_calls: int, max_calls_period: Union[float, int], min_seconds_between_calls: Union[float, int] = 0, ) -> Callable[[F], F]: """Decorator to turn an asynchronous function into a rate limited one. The decorated function won't be able to execute more than `max_calls` times over a period of `max_calls_period` seconds. The excess will be queued in FIFO mode. Aditionally, it's guaranteed that no successive calls can be performed faster than `min_seconds_between_calls` seconds. Usage: If you want to perform at most 2 calls to a database per second: >>> @rate_limited( max_calls=2, max_calls_period=1, min_seconds_between_calls=0.2, ) async def query(n): await something print(f'time: {time()}, doing: {n}') >>> await collect(map(query, range(10))) Output: ``` time: 1597706698.0, doing: 0 time: 1597706698.2, doing: 1 time: 1597706699.0, doing: 2 time: 1597706699.2, doing: 3 time: 1597706700.0, doing: 4 time: 1597706700.2, doing: 5 time: 1597706701.0, doing: 6 time: 1597706701.2, doing: 7 time: 1597706702.0, doing: 8 time: 1597706702.2, doing: 9 ``` .. tip:: Use `min_seconds_between_calls` as an anti-burst system. This can, for instance, lower your bill in DynamoDB or prevent a cooldown period (also know as ban) by a firewall. This decorator creates a `max_calls` sized data structure. """ if max_calls < 1: raise ValueError("max_calls must be >= 1") if max_calls_period <= 0: raise ValueError("max_calls_period must be > 0") if min_seconds_between_calls < 0: raise ValueError("min_seconds_between_calls must be >= 0") def decorator(function: F) -> F: lock = None waits: Deque[float] = deque() @wraps(function) async def wrapper(*args: Any, **kwargs: Any) -> Any: nonlocal lock lock = lock or asyncio.Lock() loop = asyncio.get_event_loop() async with lock: if waits: # Anti burst control system: # wait until the difference between the most recent call # and the current call is >= min_seconds_between_calls await asyncio.sleep( waits[-1] + min_seconds_between_calls - loop.time() ) while len(waits) >= max_calls: # Rate limit control system: # wait until the least recent call and the current call # is >= max_calls_period await asyncio.sleep( waits.popleft() + max_calls_period - loop.time() ) waits.append(loop.time()) return await function(*args, **kwargs) return cast(F, wrapper) return decorator async def collect(awaitables: Iterable[Awaitable[~T]], *, workers: int = 1024) ‑> Tuple[~T, ...]-
Resolve concurrently the input stream and return back in the same order.
At any point in time there will be at most number of
workerstasks being resolved concurrently.Aditionally, the algorithm makes sure that at any point in time every worker is busy.
Args
awaitables- An iterable (generator, list, tuple, set, etc) of awaitables (coroutine, asyncio.Task, or asyncio.Future).
workers- The number of independent workers that will be processing the input stream.
Returns
A tuple with the results of executing each awaitable in the event loop. Results are returned in the same order of the input stream.
Usage
>>> async def do(n): print(f'running: {n}') await sleep(1) print(f'returning: {n}') return n>>> iterable = map(do, range(5))>>> results = await collect(iterable, workers=2)>>> print(f'results: {results}')Output
running: 0 running: 1 returning: 0 returning: 1 running: 2 running: 3 returning: 2 returning: 3 running: 4 returning: 4 results: (0, 1, 2, 3, 4)Tip
This is similar to asyncio.as_completed. However results are returned in order and allows you to control how much resources are consumed throughout the execution, for instance:
- How many open files will be opened at the same time
- How many HTTP requests will be performed to a service (rate limit)
- How many sockets will be opened concurrently
- Etc
This is useful for finite resources, for instance: the number of sockets provided by the operative system is limited; going beyond it would make the kernel to kill the program abruptly.
If awaitables is an instance of Sized (has
__len__prototype). This function will launch at mostlen(awaitables)workers.Expand source code Browse git
async def collect( awaitables: Iterable[Awaitable[T]], *, workers: int = 1024, ) -> Tuple[T, ...]: """Resolve concurrently the input stream and return back in the same order. At any point in time there will be at most _number of `workers`_ tasks being resolved concurrently. Aditionally, the algorithm makes sure that at any point in time every worker is busy. Args: awaitables: An iterable (generator, list, tuple, set, etc) of awaitables (coroutine, asyncio.Task, or asyncio.Future). workers: The number of independent workers that will be processing the input stream. Returns: A tuple with the results of executing each awaitable in the event loop. Results are returned in the same order of the input stream. Usage: >>> async def do(n): print(f'running: {n}') await sleep(1) print(f'returning: {n}') return n >>> iterable = map(do, range(5)) >>> results = await collect(iterable, workers=2) >>> print(f'results: {results}') Output: ``` running: 0 running: 1 returning: 0 returning: 1 running: 2 running: 3 returning: 2 returning: 3 running: 4 returning: 4 results: (0, 1, 2, 3, 4) ``` .. tip:: This is similar to asyncio.as_completed. However results are returned in order and allows you to control how much resources are consumed throughout the execution, for instance: - How many open files will be opened at the same time - How many HTTP requests will be performed to a service (rate limit) - How many sockets will be opened concurrently - Etc This is useful for finite resources, for instance: the number of sockets provided by the operative system is limited; going beyond it would make the kernel to kill the program abruptly. If awaitables is an instance of Sized (has `__len__` prototype). This function will launch at most `len(awaitables)` workers. """ return tuple( [ await elem for elem in resolve( awaitables, workers=workers, worker_greediness=0, ) ] ) def resolve(awaitables: Iterable[Awaitable[~T]], *, workers: int = 1024, worker_greediness: int = 0) ‑> Iterable[Awaitable[~T]]-
Resolve concurrently the input stream and yield back in the same order.
At any point in time there will be at most number of
workerstasks being resolved concurrently.Aditionally, the algorithm makes sure that at any point in time every worker is busy (if greediness allow them).
Args
awaitables- An iterable (generator, list, tuple, set, etc) of awaitables (coroutine, asyncio.Task, or asyncio.Future).
workers- The number of independent workers that will be processing the input stream.
worker_greediness- How much tasks can a worker process before waiting for you to retrieve its results. 0 means unlimited. Set to non-zero in order to upper-bound memory usage throughout the execution.
Yields
A future with the result of the next ready task. Futures are yielded in the same order of the input stream.
Usage
>>> async def do(n): print(f'running: {n}') await asyncio.sleep(1) print(f'returning: {n}') return n>>> iterable = map(do, range(5))>>> for next in resolve(iterable, workers=2): try: print(f'got resolved result: {await next}') except: pass # Handle possible exceptionsOutput
running: 0 running: 1 returning: 0 returning: 1 got resolved result: 0 got resolved result: 1 running: 2 running: 3 returning: 2 returning: 3 got resolved result: 2 got resolved result: 3 running: 4 returning: 4 got resolved result: 4Tip
This is similar to asyncio.as_completed. However results are returned in order and allows you to control how much resources are consumed throughout the execution, for instance:
- How many open files will be opened at the same time
- How many HTTP requests will be performed to a service (rate limit)
- How many sockets will be opened concurrently
- Etc
This is useful for finite resources, for instance: the number of sockets provided by the operative system is limited; going beyond it would make the kernel to kill the program abruptly.
If awaitables is an instance of Sized (has
__len__prototype). This function will launch at mostlen(awaitables)workers.Expand source code Browse git
def resolve( # noqa: mccabe awaitables: Iterable[Awaitable[T]], *, workers: int = 1024, worker_greediness: int = 0, ) -> Iterable[Awaitable[T]]: """Resolve concurrently the input stream and yield back in the same order. At any point in time there will be at most _number of `workers`_ tasks being resolved concurrently. Aditionally, the algorithm makes sure that at any point in time every worker is busy (if greediness allow them). Args: awaitables: An iterable (generator, list, tuple, set, etc) of awaitables (coroutine, asyncio.Task, or asyncio.Future). workers: The number of independent workers that will be processing the input stream. worker_greediness: How much tasks can a worker process before waiting for you to retrieve its results. 0 means unlimited. Set to non-zero in order to upper-bound memory usage throughout the execution. Yields: A future with the result of the next ready task. Futures are yielded in the same order of the input stream. Usage: >>> async def do(n): print(f'running: {n}') await asyncio.sleep(1) print(f'returning: {n}') return n >>> iterable = map(do, range(5)) >>> for next in resolve(iterable, workers=2): try: print(f'got resolved result: {await next}') except: pass # Handle possible exceptions Output: ``` running: 0 running: 1 returning: 0 returning: 1 got resolved result: 0 got resolved result: 1 running: 2 running: 3 returning: 2 returning: 3 got resolved result: 2 got resolved result: 3 running: 4 returning: 4 got resolved result: 4 ``` .. tip:: This is similar to asyncio.as_completed. However results are returned in order and allows you to control how much resources are consumed throughout the execution, for instance: - How many open files will be opened at the same time - How many HTTP requests will be performed to a service (rate limit) - How many sockets will be opened concurrently - Etc This is useful for finite resources, for instance: the number of sockets provided by the operative system is limited; going beyond it would make the kernel to kill the program abruptly. If awaitables is an instance of Sized (has `__len__` prototype). This function will launch at most `len(awaitables)` workers. """ if workers < 1: raise ValueError("workers must be >= 1") if worker_greediness < 0: raise ValueError("worker_greediness must be >= 0") if hasattr(awaitables, "__len__"): workers = min(workers, len(awaitables)) # type: ignore loop = asyncio.get_event_loop() store: Dict[int, asyncio.Queue] = {} stream, stream_copy = tee(enumerate(awaitables)) stream_finished = asyncio.Event() workers_up = asyncio.Event() workers_tasks: Dict[int, asyncio.Task] = {} async def worker() -> None: done: asyncio.Queue = asyncio.Queue(worker_greediness) for index, awaitable in stream: store[index] = done future = loop.create_future() future.set_result(await schedule(awaitable, loop=loop)) await done.put(future) workers_up.set() workers_up.set() stream_finished.set() async def start_workers() -> None: for index in range(workers): if stream_finished.is_set(): break workers_tasks[index] = asyncio.create_task(worker()) await force_loop_cycle() await workers_up.wait() async def get_one(index: int) -> Awaitable[T]: if not workers_tasks: await start_workers() awaitable = await store.pop(index).get() result: Awaitable[T] = (await awaitable).result() return result for index, _ in stream_copy: yield cast(Awaitable[T], get_one(index)) async def force_loop_cycle() ‑> NoneType-
Force the event loop to perform one cycle.
This can be used to suspend the execution of the current coroutine and yield control back to the event-loop until the next cycle.
Can be seen as a forceful switch of control between threads. Useful for cooperative initialization.
Usage
>>> await forceforce_loop_cycle()Expand source code Browse git
async def force_loop_cycle() -> None: """Force the event loop to perform one cycle. This can be used to suspend the execution of the current coroutine and yield control back to the event-loop until the next cycle. Can be seen as a forceful switch of control between threads. Useful for cooperative initialization. Usage: >>> await forceforce_loop_cycle() """ await asyncio.sleep(0) async def generate_in_thread(generator_func: Callable[..., Generator[~Y, ~S, NoneType]], *args: Any, **kwargs: Any) ‑> AsyncGenerator[~Y, ~S]-
Mimic
generator_func(*args, **kwargs)in the configured thread pool.Note that
generator_func(*args, **kwargs)may return a generator or an interator and both cases are handled rightfully.Usage
>>> from os import scandir>>> async for entry in generate_in_thread(scandir, '.'): print(entry.name)Output
.gitignore LICENSE.md README.md ...Calls to the generator are done serially and not concurrently.
The benefit of wrapping a generator with this function is that the event-loop is free to schedule and wait another tasks in the mean time. For instance, in a web server.
Expand source code Browse git
async def generate_in_thread( generator_func: Callable[..., Generator[Y, S, None]], *args: Any, **kwargs: Any, ) -> AsyncGenerator[Y, S]: """Mimic `generator_func(*args, **kwargs)` in the configured thread pool. Note that `generator_func(*args, **kwargs)` may return a generator or an interator and both cases are handled rightfully. Usage: >>> from os import scandir >>> async for entry in generate_in_thread(scandir, '.'): print(entry.name) Output: ``` .gitignore LICENSE.md README.md ... ``` Calls to the generator are done serially and not concurrently. The benefit of wrapping a generator with this function is that the event-loop is free to schedule and wait another tasks in the mean time. For instance, in a web server. """ gen: Generator[Y, S, None] = generator_func(*args, **kwargs) gen_sent: Any = None def gen_next(val: S) -> Y: with suppress(StopIteration): return gen.send(val) if hasattr(gen, "send") else next(gen) raise StopAsyncIteration() while True: try: gen_sent = yield await in_thread(gen_next, gen_sent) except StopAsyncIteration: return def schedule(awaitable: Awaitable[~T], *, loop: Union[asyncio.events.AbstractEventLoop, NoneType] = None) ‑> Awaitable[asyncio.Future[T]]-
Schedule an awaitable in the event loop and return a wrapper for it.
Usage
>>> async def do(n): print(f'running: {n}') await sleep(1) print(f'returning: {n}')>>> task = schedule(do(3)) # Task is executing in the background now>>> print('other work is being done here')>>> task_result = await task # Wait until the task is ready>>> print(f'result: {task_result.result()}') # may rise if do() raisedOutput
other work is being done here doing: 3 returning: 3 3This works very similar to asyncio.create_task. The main difference is that the result (or exception) can be accessed via exception() or result() methods.
If an exception was raised by the awaitable, it will be propagated only at the moment result() is called and never otherwise.
Expand source code Browse git
def schedule( awaitable: Awaitable[T], *, loop: Optional[asyncio.AbstractEventLoop] = None, ) -> "Awaitable[asyncio.Future[T]]": """Schedule an awaitable in the event loop and return a wrapper for it. Usage: >>> async def do(n): print(f'running: {n}') await sleep(1) print(f'returning: {n}') >>> task = schedule(do(3)) # Task is executing in the background now >>> print('other work is being done here') >>> task_result = await task # Wait until the task is ready >>> print(f'result: {task_result.result()}') # may rise if do() raised Output: ``` other work is being done here doing: 3 returning: 3 3 ``` This works very similar to asyncio.create_task. The main difference is that the result (or exception) can be accessed via exception() or result() methods. If an exception was raised by the awaitable, it will be propagated only at the moment result() is called and never otherwise. """ wrapper = (loop or asyncio.get_event_loop()).create_future() def _done_callback(future: asyncio.Future) -> None: if not wrapper.done(): # pragma: no cover wrapper.set_result(future) asyncio.create_task(awaitable).add_done_callback(_done_callback) return wrapper def run_decorator(function: ~F) ‑> ~F-
Decorator to turn an asynchronous function into a synchronous one.
Usage
>>> @run_decorator async def do(a, b=0): return a + b>>> do(1, b=2)Output
3This can be used as a bridge between synchronous and asynchronous code. We use it mostly in tests for its convenience over pytest-asyncio plugin.
Expand source code Browse git
def run_decorator(function: F) -> F: """Decorator to turn an asynchronous function into a synchronous one. Usage: >>> @run_decorator async def do(a, b=0): return a + b >>> do(1, b=2) Output: ``` 3 ``` This can be used as a bridge between synchronous and asynchronous code. We use it mostly in tests for its convenience over pytest-asyncio plugin. """ @wraps(function) def wrapper(*args: Any, **kwargs: Any) -> Any: return run(function(*args, **kwargs)) return cast(F, wrapper)
Classes
class Semaphore (value=1, *, loop=None)-
Same as
asyncio.Semaphoreplus some useful methods.Expand source code Browse git
class Semaphore(asyncio.Semaphore): """Same as `asyncio.Semaphore` plus some useful methods.""" @asynccontextmanager async def acquire_many(self, times: int) -> AsyncIterator[None]: """Acquire a semaphore many times, and release on exit. Usage: >>> async with semaphore.acquire_many(5): # Work with shared resource ... """ if times <= 0: raise ValueError("times must be >= 1") try: await collect([self.acquire() for _ in range(times)]) yield finally: for _ in range(times): self.release()Ancestors
- asyncio.locks.Semaphore
- asyncio.locks._ContextManagerMixin
Subclasses
Methods
async def acquire_many(self, times: int) ‑> AsyncIterator[NoneType]-
Acquire a semaphore many times, and release on exit.
Usage
>>> async with semaphore.acquire_many(5): # Work with shared resource ...Expand source code Browse git
@asynccontextmanager async def acquire_many(self, times: int) -> AsyncIterator[None]: """Acquire a semaphore many times, and release on exit. Usage: >>> async with semaphore.acquire_many(5): # Work with shared resource ... """ if times <= 0: raise ValueError("times must be >= 1") try: await collect([self.acquire() for _ in range(times)]) yield finally: for _ in range(times): self.release()
class BoundedSemaphore (value=1, *, loop=None)-
Same as
asyncio.BoundedSemaphoreplus some useful methods.Expand source code Browse git
class BoundedSemaphore(Semaphore, asyncio.BoundedSemaphore): """Same as `asyncio.BoundedSemaphore` plus some useful methods."""Ancestors
- Semaphore
- asyncio.locks.BoundedSemaphore
- asyncio.locks.Semaphore
- asyncio.locks._ContextManagerMixin
Inherited members
class ExecutorPool (cls: Union[Type[concurrent.futures.process.ProcessPoolExecutor], Type[concurrent.futures.thread.ThreadPoolExecutor]])-
Object representing a pool of Processes or Threads.
The actual pool is created at
initializationtime and it is empty until that.Expand source code Browse git
class ExecutorPool: """Object representing a pool of Processes or Threads. The actual pool is created at `initialization` time and it is empty until that. """ def __init__( self, cls: Union[ Type[ProcessPoolExecutor], Type[ThreadPoolExecutor], ], ) -> None: self._cls = cls self._pool: Optional[Executor] = None def initialize(self, *, max_workers: Optional[int] = None) -> None: """Initialize the executor with a cap of at most `max_workers`. Workers are created on-demand as needed or never created at all if never needed. """ if self._pool is not None: self._pool.shutdown(wait=False) self._pool = self._cls(max_workers=max_workers) def shutdown(self, *, wait: bool) -> None: """Shut down the executor and (optionally) waits for workers to finish.""" if self._pool is not None: self._pool.shutdown(wait=wait) self._pool = None @property def pool(self) -> Executor: """Low level pool of workers held by the executor, may be None.""" if self._pool is None: raise RuntimeError("Must call initialize first") return self._pool @property def initialized(self) -> bool: """Return true if the executor is initialized and ready to process.""" return self._pool is not NoneInstance variables
var pool : concurrent.futures._base.Executor-
Low level pool of workers held by the executor, may be None.
Expand source code Browse git
@property def pool(self) -> Executor: """Low level pool of workers held by the executor, may be None.""" if self._pool is None: raise RuntimeError("Must call initialize first") return self._pool var initialized : bool-
Return true if the executor is initialized and ready to process.
Expand source code Browse git
@property def initialized(self) -> bool: """Return true if the executor is initialized and ready to process.""" return self._pool is not None
Methods
def initialize(self, *, max_workers: Union[int, NoneType] = None) ‑> NoneType-
Initialize the executor with a cap of at most
max_workers.Workers are created on-demand as needed or never created at all if never needed.
Expand source code Browse git
def initialize(self, *, max_workers: Optional[int] = None) -> None: """Initialize the executor with a cap of at most `max_workers`. Workers are created on-demand as needed or never created at all if never needed. """ if self._pool is not None: self._pool.shutdown(wait=False) self._pool = self._cls(max_workers=max_workers) def shutdown(self, *, wait: bool) ‑> NoneType-
Shut down the executor and (optionally) waits for workers to finish.
Expand source code Browse git
def shutdown(self, *, wait: bool) -> None: """Shut down the executor and (optionally) waits for workers to finish.""" if self._pool is not None: self._pool.shutdown(wait=wait) self._pool = None